From Demos to Simulation Engines: How Robot Data Generation Is Becoming a Sim Stack
Robot learning has a data problem, but from a simulation perspective the problem is more specific: we do not yet have enough reliable ways to turn simulated worlds into useful robot behavior data.
Real robot demonstrations are expensive, narrow, and difficult to scale. But simply saying “use simulation” does not solve the problem. A simulator is not automatically a data engine. It only becomes useful when it can answer several hard questions at the same time:
| Simulation question | Why it matters |
|---|---|
| What world is the robot acting in? | Scene geometry, object assets, materials, lighting, and camera setup define the observation distribution. |
| Who generates the behavior? | Data may come from teleoperation replay, scripted experts, planners, RL policies, human videos, or reconstructed real episodes. |
| Is the behavior physically valid? | Kinematic replay may look plausible but fail under contact, dynamics, friction, or embodiment changes. |
| Can the data scale? | A useful pipeline must generate many task variations, object placements, and trajectories without human editing. |
| Can it transfer back to reality? | Synthetic data is only valuable if it improves real or realistic downstream policy performance. |
This is why recent robot data-generation work should not be read only as “new augmentation methods.” A better way to read it is as a search for simulation-based behavior-data engines.
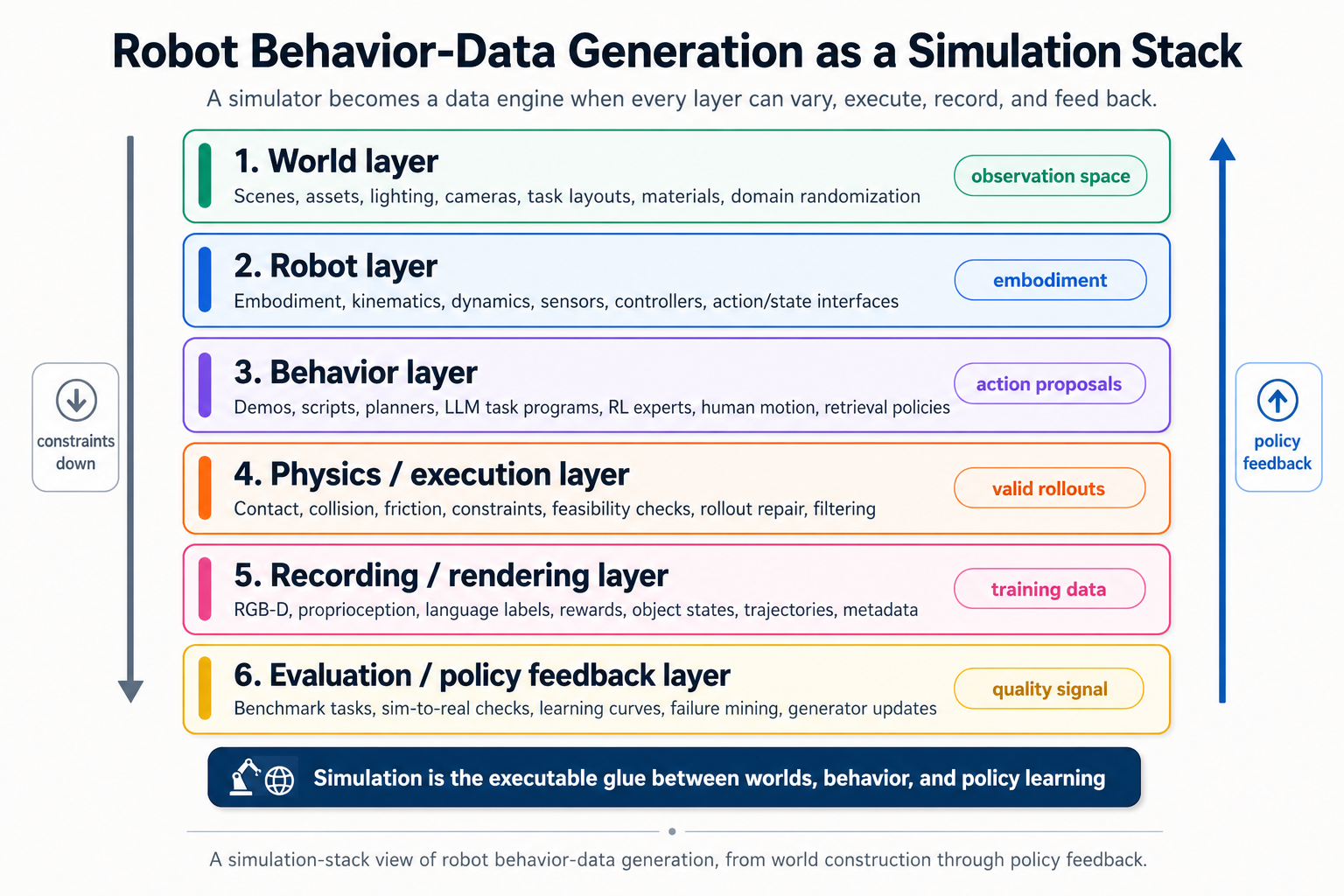
A behavior-data engine is more than a simulator. It is a pipeline that combines simulated worlds, behavior generators, physics constraints, rendering, task variation, and policy training into a repeatable system for producing robot-learning data.
Post-2024 work is moving from “augment a few teleop demonstrations” toward several kinds of simulation engines:
| Engine type | Simulation role | Typical output |
|---|---|---|
| Demo-to-sim replay engines | Use simulation to replay and transform seed demonstrations | Expanded robot trajectories |
| Programmatic expert factories | Use simulation as a mass-production environment for scripted/planned experts | Large-scale expert episodes |
| RL rollout and distillation factories | Use simulation as an interactive training ground for task experts | Policy rollouts for distillation |
| Real-to-sim reconstruction engines | Use real data to build or constrain simulation scenes | Grounded synthetic episodes |
| Human-to-sim-to-robot engines | Use simulation to convert human behavior into robot-executable behavior | Retargeted or RL-generated robot data |
These categories are not perfectly separate. In fact, the best systems increasingly combine them. A real-to-sim method may train RL experts inside the reconstructed environment. A human-video method may use simulation to infer missing robot actions. A demo-transformation method may add physics optimization to repair invalid replay. But the taxonomy is still useful because it highlights the central trend: robot data generation is becoming a simulation stack.
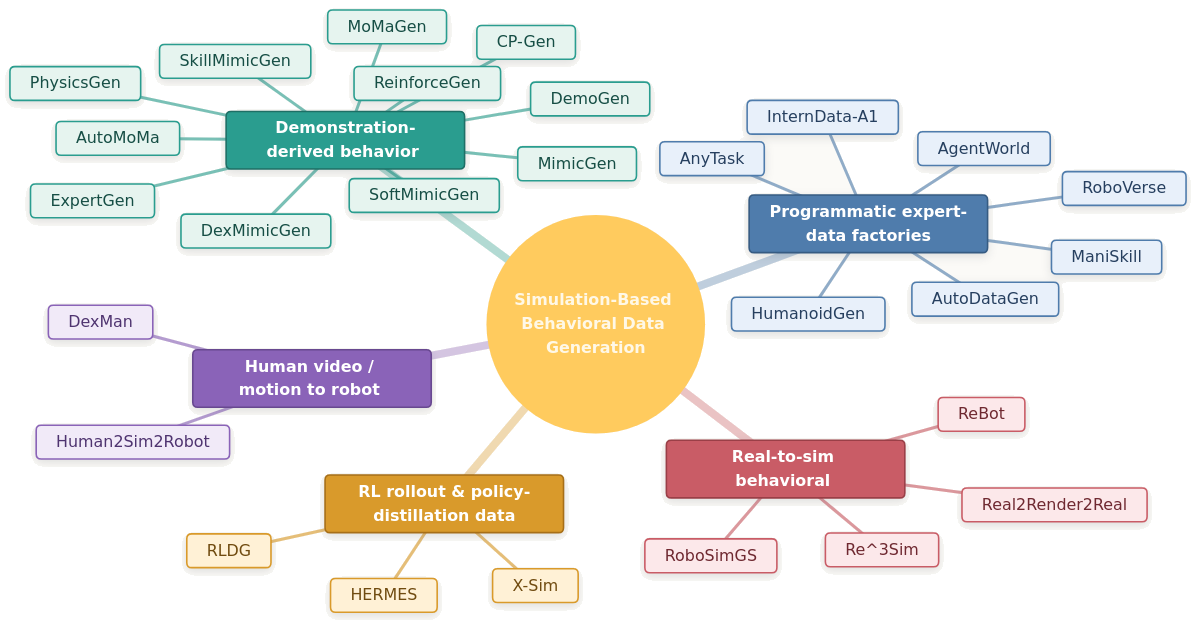 A taxonomy view of robot behavior-data generation methods as simulation engines.
A taxonomy view of robot behavior-data generation methods as simulation engines.
1. The simulation view: data generation is not one module
A lot of robot-learning discussions treat simulation as a background tool: first build an environment, then train or collect data inside it. But for synthetic data generation, simulation is not just the place where things happen. It defines the entire data distribution.
A practical simulation-based data engine has at least five layers:
| Layer | Core responsibility | Failure mode if weak |
|---|---|---|
| World layer | Scenes, objects, layouts, lighting, cameras, materials | Visually rich but physically irrelevant data, or physically valid but visually unrealistic data |
| Robot layer | Embodiment, kinematics, dynamics, sensors, controllers | Trajectories that cannot transfer across robots or cannot be executed on the target robot |
| Behavior layer | Demos, planners, scripts, RL policies, human motion, task programs | Large amounts of data with poor task diversity or unrealistic strategies |
| Physics/execution layer | Contact, friction, constraints, collision, dynamics, feasibility checks | Kinematic trajectories that fail when actually simulated |
| Evaluation layer | Benchmark tasks, success metrics, real/sim correlation, policy feedback | Data generation without evidence that the data helps policies |
Most recent papers can be interpreted by asking: which layer are they trying to strengthen?
MimicGen-style methods strengthen the behavior layer by transforming demonstrations. PhysicsGen strengthens the physics/execution layer by making trajectories dynamically feasible. InternData-A1 and AnyTask strengthen the behavior layer through scripted or planned experts. ReBot and Re³Sim strengthen the world layer by grounding simulation in real scenes. X-Sim and Human2Sim2Robot use simulation as the bridge between human observation and robot action.
This simulation-centered view makes the field easier to reason about. The key question is no longer only “how many demonstrations can this method generate?” The better question is:
What does this method use simulation for, and which part of the synthetic-data stack does it make more scalable or more realistic?
2. Demo-to-sim replay engines: scaling from high-quality seed demonstrations
The most natural starting point for simulation-based robot data generation is demonstration replay.
If a human teleoperates a robot successfully in simulation, we already have something valuable: a physically executable trajectory, a valid task solution, and a demonstration aligned with the robot embodiment. The question is whether simulation can turn that small amount of seed data into a much larger dataset.
This is the core idea behind the MimicGen family.
MimicGen: simulation as a demonstration multiplier
MimicGen is the foundational system in this direction. It starts from a few human demonstrations, decomposes them into object-centric segments, and applies spatial transformations so that the same behavior can be replayed under new object poses.
From a simulation perspective, MimicGen is powerful because it treats the simulator as a trajectory validation and execution environment. The seed behavior comes from humans, but the scaling comes from simulated variation. The system can move objects, transform subtrajectories, replay the behavior, and check whether the generated rollout succeeds.
The main assumption is that many manipulation demonstrations contain reusable local structure. If the robot has learned or recorded how to grasp an object in one pose, a transformed version of that segment may still work when the object appears somewhere else.
This is a strong idea, but it also reveals the limits of pure kinematic replay. Object pose variation is only one axis of variation. Realistic simulation-based data generation must also handle contact, object geometry, deformability, mobile bases, robot embodiment changes, visual diversity, and failure recovery.
Many later works can be understood as expanding MimicGen along one of these simulation axes.
SkillMimicGen: using simulation to separate motion planning from learned contact
SkillMimicGen introduces a Hybrid Skill Policy that isolates learning to contact-rich skill segments while relying on traditional motion planning for free-space movement.
This is important from a simulation-engineering view. It says that data generation does not need to learn everything end-to-end. A simulator can combine:
| Component | Best handled by |
|---|---|
| Free-space transit | Motion planning |
| Contact-rich manipulation | Learned skill policy |
| Object placement variation | Simulation reset and randomization |
| Execution validation | Simulator rollout |
This division is practical. In simulation, free-space paths can often be generated cheaply by planners. The hard part is contact: grasping, insertion, pushing, alignment, and recovery. By focusing the learned component on those segments, SkillMimicGen makes the data engine more modular.
The broader lesson is that the best simulation data engines may not be purely learned or purely scripted. They may be hybrid systems where planners handle geometry, learned policies handle contact, and the simulator validates the final trajectory.
DexMimicGen: simulation replay for bimanual dexterity
DexMimicGen extends automated data generation to bimanual dexterous manipulation. This matters because bimanual tasks create simulation challenges that single-arm tabletop tasks often avoid.
A bimanual simulator rollout must handle two arms, coordinated subtasks, self-collision, object stability, and often longer-horizon contact sequences. If the robot is humanoid-like, the problem becomes even harder because the action space and body constraints are more complex.
From a simulation perspective, DexMimicGen is not merely “MimicGen with more hands.” It tests whether demonstration-derived replay can survive a richer embodiment and a more constrained physical interaction space.
This is one of the central questions for humanoid robot data generation: can we still scale from seed demonstrations, or do we need fundamentally different engines for high-DOF bimanual behavior?
CP-Gen: simulation under object-geometry variation
Rigid object-pose transformation is useful, but it breaks when the object shape changes. A trajectory that works for one handle, tool, or container may not work for another geometry.
CP-Gen addresses this by replacing simple rigid transformations with keypoint-trajectory constraints. Instead of assuming that the whole object can be treated as a rigid frame, it constrains important points and adapts the trajectory to new object geometries.
From the simulation view, CP-Gen strengthens the asset variation problem. A useful simulator should not only randomize where an object is placed. It should support behavior generation across object instances with different shapes.
This is crucial for production-scale synthetic data. If data generation only works for one object mesh, the simulator becomes a narrow demo replay tool. If it can adapt behavior across object geometry, it becomes closer to a scalable data factory.
SoftMimicGen: simulation with deformable objects
SoftMimicGen moves the same question into deformable-object manipulation. Towels, ropes, cloth, and other soft objects cannot be represented by a single rigid pose. Their state is distributed across shape, folds, tension, and contact.
This changes the simulation problem. Rigid replay is no longer enough. The data engine must adapt trajectories to non-rigid state variation.
SoftMimicGen does this with non-rigid registration and trajectory warping. In simulation terms, it asks whether a demonstration can deform together with the object state.
This direction is important because deformable-object manipulation is exactly the kind of domain where real data collection is slow and simulation is tempting, but also exactly where simulation fidelity is difficult. A useful deformable-object data engine must control not only the trajectory but also the object-state distribution.
DemoGen: reducing dependency on expensive rollout generation
DemoGen attacks a different simulation bottleneck: generating visual variation can be expensive if every new observation requires a full simulator rollout.
By using 3D point cloud editing to synthesize new visual observations, DemoGen suggests a lighter-weight way to produce visual diversity. This matters because robot policies often consume images. The trajectory is only part of the data; the visual observation distribution is equally important.
From a simulation-stack perspective, DemoGen separates part of the visual world layer from the physical execution layer. Not every visual data augmentation needs full physics replay. If the action sequence remains valid, visual observations may sometimes be expanded by editing the 3D scene representation.
This separation is useful, but it also creates a question: when does visual editing preserve the action semantics, and when does it create images that no longer correspond to physically valid interaction? That boundary is one of the hard problems in synthetic data generation.
MoMaGen and AutoMoMa: simulation for mobile manipulation constraints
Mobile manipulation forces data generation to reason about the whole embodied system. The robot must choose where to stand, what it can see, what it can reach, how its arms move, and how the object changes over time.
MoMaGen frames mobile bimanual manipulation as constrained optimization, enforcing hard reachability constraints and soft visibility constraints. AutoMoMa moves toward a more unified representation by jointly optimizing the mobile base, arms, and object through an Augmented Kinematic Representation.
From a simulation perspective, both methods reflect the same shift: behavior generation can no longer be treated as an end-effector trajectory problem. The simulator must expose constraints involving base placement, arm reachability, camera visibility, collision, and object motion.
For mobile manipulation, the world layer and behavior layer become tightly coupled. A trajectory is only valid relative to a scene layout, a body configuration, a camera model, and a controller.
ReinforceGen and ExpertGen: adding feedback inside simulation
Offline replay can generate many trajectories, but it may not discover recovery behavior. If a transformed trajectory slightly misses a grasp or enters an unstable contact state, pure replay may fail.
ReinforceGen adds online feedback by using reinforcement learning to fine-tune components of the Hybrid Skill Policy. ExpertGen similarly uses RL to steer the behavior distribution of a frozen state-based diffusion model, discovering safer or more robust behaviors from imperfect priors.
From the simulation view, this is a critical transition. The simulator is no longer only a replay environment. It becomes a feedback environment. Generated behavior can be tested, repaired, and improved through interaction.
This is likely to become a standard pattern: use demonstrations or scripts to initialize behavior, then use simulation feedback to expand the valid region around that behavior.
PhysicsGen: simulation as a physics optimizer, not just a visualizer
PhysicsGen makes the simulation role even more explicit. Instead of relying on rigid kinematic replay, it uses physics-driven trajectory optimization to generate dynamically feasible, contact-rich data and transfer demonstrations across robot embodiments.
This addresses one of the most important weaknesses of many synthetic-data pipelines: a trajectory can look reasonable geometrically while being physically invalid. It may require impossible forces, unstable contacts, or embodiment-specific motions that cannot transfer.
PhysicsGen represents a more serious use of simulation. The simulator is not just rendering images or replaying positions. It is enforcing physical feasibility.
For real robot learning, this distinction matters. A visually plausible trajectory is not enough. The policy eventually has to act through motors, contacts, friction, compliance, and delays. A simulation data engine that ignores these factors may scale the wrong kind of data.
Summary: demo-to-sim replay as an expanding simulation problem
The MimicGen lineage can be summarized as a history of simulation failure modes:
| Simulation limitation | Representative direction |
|---|---|
| Only object pose changes | MimicGen-style rigid transformation |
| Contact segments are hard | SkillMimicGen-style skill decomposition |
| Single-arm setting is limited | DexMimicGen-style bimanual generation |
| Object geometry changes | CP-Gen-style keypoint constraints |
| Objects deform | SoftMimicGen-style non-rigid warping |
| Visual variation is expensive | DemoGen-style 3D observation editing |
| Mobile manipulation couples base, arm, and camera | MoMaGen / AutoMoMa-style constrained generation |
| Offline replay lacks robustness | ReinforceGen / ExpertGen-style feedback refinement |
| Kinematic replay may be physically invalid | PhysicsGen-style physics optimization |
This family remains practical because it starts from high-quality demonstrations. Its weakness is that it still needs seed data, and its generalization is bounded by what the simulator can validly transform, replay, and repair.
3. Programmatic expert factories: simulation as a mass-production line
Demo-to-sim replay starts from human or robot demonstrations. Programmatic expert factories ask a more aggressive question:
Can we generate expert robot behavior directly inside simulation, without relying on a large set of human demonstrations?
This is where simulation becomes a mass-production line. Instead of manually collecting every episode, the system uses task generators, planners, scripted skills, motion planning, LLM decomposition, and sometimes RL experts to produce large volumes of structured robot data.
This family is especially relevant for generalist robot policy pretraining. A generalist policy needs breadth: many tasks, objects, instructions, scene layouts, and action patterns. Human teleoperation alone is unlikely to provide that breadth cheaply.
InternData-A1: scripted skills plus collision-aware planning
InternData-A1 generates large-scale language-conditioned synthetic trajectories by composing scripted skill policies and collision-aware motion plans in simulation.
From a simulation standpoint, this is a classic expert-factory design. It relies on a well-instrumented simulator where the system has access to object state, robot state, collision checking, and motion planning. The resulting trajectories are not merely random rollouts; they are structured expert demonstrations generated from known task programs.
The language-conditioned aspect is important. If the data is meant for vision-language-action models, each trajectory should be paired with task intent. Simulation can provide this pairing naturally because the task generator knows what it asked the robot to do.
AutoDataGen: LLM task decomposition into Isaac Lab action sequences
AutoDataGen uses LLM task decomposition with planning and navigation modules to generate Isaac Lab action sequences and trajectories.
This is interesting because it places Isaac Lab-like simulation at the center of an automated data pipeline. The LLM can propose or decompose tasks, but the simulator remains the place where those tasks must become executable robot actions.
The key engineering idea is layered generation:
| Layer | Example role |
|---|---|
| Task language | Describe the goal |
| Task decomposition | Break the goal into substeps |
| Planning/navigation | Produce feasible movement |
| Controller/action layer | Convert plans into robot actions |
| Simulation rollout | Validate the episode |
From a simulation view, the LLM is not the data engine by itself. It is a high-level task generator. The real data engine is the coupling between task decomposition, robot planners, and simulator validation.
AnyTask: foundation-model task design plus TAMP and RL experts
AnyTask combines foundation-model task design with task-and-motion planning and RL expert agents in massively parallel simulation.
This is a good example of where the field is heading. Pure scripting is too brittle. Pure RL can be too expensive. Pure LLM planning is not physically reliable. A practical simulation factory uses each component for what it does best:
| Component | Useful for |
|---|---|
| Foundation model | Task diversity and semantic variation |
| TAMP | Symbolic and geometric feasibility |
| RL expert | Interaction-heavy control |
| Massive parallel simulation | Scale and filtering |
The simulator is the arbitration layer. It decides whether a generated task and behavior actually work under geometry and physics.
HumanoidGen: simulation factories for high-DOF humanoid manipulation
HumanoidGen targets humanoid bimanual dexterous demonstrations using LLM task reasoning and trajectory optimization in SAPIEN.
Humanoid manipulation is a strong test case for programmatic expert factories. The robot body is high-dimensional, the tasks are contact-rich, and the space of possible behaviors is large. Manual teleoperation can provide useful data, but it is hard to scale across enough tasks and object variations.
A simulation factory for humanoids must solve several problems at once:
| Challenge | Simulation requirement |
|---|---|
| High-DOF control | Stable controllers and trajectory optimization |
| Bimanual coordination | Whole-body or multi-limb planning |
| Contact-rich manipulation | Reliable contact simulation and feasibility checking |
| Task diversity | Automated task generation and validation |
| Policy learning | Exportable trajectories and observations |
HumanoidGen-style systems are therefore not just data generators. They are attempts to make humanoid simulation productive enough for large-scale learning.
RoboVerse, ManiSkill, and AgentWorld: environments as data-generation infrastructure
RoboVerse, ManiSkill, and AgentWorld highlight another point: data factories need ecosystems.
A single algorithm is not enough. A useful simulation data platform needs assets, tasks, reset logic, reward definitions, controllers, parallel execution, evaluation metrics, and policy interfaces. These environments are not only benchmarks; they are potential data-generation substrates.
This distinction matters. In traditional robotics, a benchmark is where you test a policy. In modern simulation-driven robot learning, a benchmark-like environment may also be where you generate the training data.
The boundary between training environment, data factory, and evaluation benchmark is becoming blurry.
Strength and weakness of programmatic expert factories
Programmatic factories are attractive because they can scale. Once the simulator, task generator, and expert policies work, the marginal cost of generating more data can be low.
But their weakness is distribution bias. The generated data may reflect the habits of the scripts, the assumptions of the planners, the simplifications of the simulator, and the clean structure of the task generator.
A scripted expert can produce thousands of successful episodes that all fail to include the messy states real robots face: partial grasps, occlusions, object slips, perception errors, human clutter, and recovery after failed contact.
So the key question is not only:
Can this factory generate successful episodes?
The more important question is:
Does this simulation factory generate the right failures, recoveries, contacts, and long-tail variation for downstream policies?
4. RL rollout and distillation factories: simulation as an interaction generator
The third family uses simulation not primarily for replay or scripting, but for interaction.
The core idea is:
Train task-specific experts in simulation, roll them out, and distill their behavior into a broader policy.
This turns RL into a data-generation mechanism. Instead of viewing RL only as the final policy-training method, these systems use RL policies as synthetic data producers.
RLDG: task-specific RL experts as data sources
RLDG trains task-specific reinforcement-learning policies, generates simulated expert rollout data, and distills those trajectories into a generalist robot policy.
From a simulation perspective, this is a clean and important pattern:
| Stage | Simulation role |
|---|---|
| Expert training | Provide interactive task environments and rewards |
| Rollout generation | Produce diverse state-action trajectories |
| Distillation | Convert many expert behaviors into one generalist policy |
| Evaluation | Test whether distilled behavior generalizes |
The strength of this pattern is that RL can discover behaviors that are difficult to script manually. It can also generate recovery states, contact-rich strategies, and non-obvious solutions.
The weakness is that RL is only as good as the simulator and reward. If the reward is misspecified or the physics is exploitable, the expert may produce data that is technically successful but not useful for real-world learning.
X-Sim: simulation as the bridge from human video to robot action
X-Sim reconstructs human RGB-D videos into photorealistic simulation, generates rewards and RL rollouts, and distills state policies into image diffusion policies.
This is one of the most interesting patterns because the input is not a robot demonstration. It is human video. Human videos are abundant, but they lack robot actions. Simulation fills the missing middle:
- Reconstruct the scene from human video.
- Infer task structure or rewards.
- Train a robot expert in simulation.
- Roll out the expert to generate robot actions.
- Distill the behavior into an image-conditioned policy.
From the simulation view, X-Sim turns simulation into an action inference engine. It uses the reconstructed world and task objective to generate the robot behavior that was not present in the original human video.
This is a powerful idea, but the quality depends on multiple links: reconstruction fidelity, reward correctness, physical simulation, embodiment retargeting, and policy distillation.
HERMES: RL as an embodiment-adaptation layer
HERMES generates physically plausible mobile bimanual dexterous behaviors by transforming heterogeneous human motion data through unified RL and sim-to-real transfer.
The key challenge here is embodiment mismatch. Human motion does not directly map to robot motion. A human hand, arm, torso, and base do not share the same kinematic and dynamic constraints as a robot.
RL can serve as an adaptation layer. Instead of directly copying human motion, the simulator uses human behavior as a prior or objective, then optimizes robot-executable behavior under the robot’s body constraints.
This is a general pattern for human-to-robot data generation: human data provides intent and structure; simulation and RL convert that intent into physically valid robot action.
Why RL factories matter
RL rollout factories are valuable because they generate interaction data, not just transformed trajectories. They can expose the policy to states that demonstrations may not contain.
But they are also fragile. Their main risks are:
| Risk | Consequence |
|---|---|
| Reward hacking | Expert behavior succeeds in simulation for the wrong reason |
| Physics exploitation | The generated data depends on simulator artifacts |
| Poor visual grounding | State experts may not transfer to image policies |
| Expensive training | Many tasks require many experts |
| Weak sim-to-real correlation | Rollouts may not improve real performance |
This is why RL factories should not be viewed as replacing demonstrations, real data, or scripted experts. Their best role is complementary: use them to fill in interaction, recovery, and contact behaviors that are hard to collect or script.
5. Real-to-sim reconstruction engines: simulation grounded by real data
Synthetic simulation data is scalable, but scale can be dangerous if the simulator distribution is wrong. A million unrealistic episodes are not necessarily better than a thousand well-grounded real ones.
Real-to-sim reconstruction addresses this by starting from real scenes, real robot videos, or real object configurations, then reconstructing them inside simulation. The simulator becomes an editable and replayable version of reality.
This family strengthens the world layer of the simulation stack.
ReBot: replaying real robot datasets in Isaac Sim / Isaac Lab
ReBot reconstructs real robot video-action episodes from datasets such as DROID and BridgeData inside Isaac Sim / Isaac Lab. Once the real episodes are reconstructed, the system can swap objects or backgrounds and generate counterfactual data for VLA fine-tuning.
From a simulation perspective, this is extremely important. It treats real datasets not as static logs, but as seeds for simulation editing.
The original real episode provides grounding:
| Real data provides | Simulation adds |
|---|---|
| Camera viewpoint | Object/background variation |
| Robot motion | Counterfactual scene edits |
| Task structure | Additional synthetic episodes |
| Real distribution anchor | Controllable data expansion |
This is one of the most practical roles for real-to-sim: use expensive real data as the anchor, then use simulation to multiply it.
RoboSimGS: visual reconstruction plus interaction
RoboSimGS builds simulated robot-learning demonstrations from multi-view real images by reconstructing 3DGS-plus-mesh interactive environments.
The key tension here is between visual realism and physical usability. 3D Gaussian Splatting can produce strong visual reconstructions, but robot learning also needs collision, contact, and object manipulation. A visually realistic scene is not automatically an interactive simulation.
RoboSimGS-style systems therefore point to an important direction: simulation worlds may need hybrid representations. One representation may serve rendering quality; another may serve physics and interaction.
For robot learning, the best world model is not simply the prettiest render. It is a representation that supports both perception and action.
Real2Render2Real: rendering and retargeting without full dynamics
Real2Render2Real generates robot-agnostic demonstrations by scanning scenes, tracking 6-DoF object motion, rendering with IsaacLab, and retargeting through inverse kinematics.
This is interesting because it does not necessarily require full dynamics simulation. It uses real object motion and scene reconstruction, then generates robot-compatible observations and actions through rendering and IK retargeting.
From a simulation-stack view, this separates several functions:
| Function | Possible implementation |
|---|---|
| Real scene capture | Scanning or reconstruction |
| Object motion | Tracking 6-DoF trajectories |
| Visual observation generation | Rendering |
| Robot action generation | IK retargeting |
| Dynamics validation | Optional or limited |
This kind of system may be useful when visual and kinematic alignment matter more than detailed contact dynamics. But for force-sensitive tasks, the lack of full dynamics may become a limitation.
Re³Sim: digital twins for privileged expert data
Re³Sim reconstructs high-fidelity 3DGS digital twins in Isaac Sim / PhysX and collects expert data using privileged simulation state.
This is a strong example of simulation as a bridge between real-world appearance and privileged-state expert generation. In the real world, we do not usually have perfect object poses, collision geometry, or privileged task state. In simulation, once a scene is reconstructed, we can use privileged information to generate expert behavior.
This is one of the strongest arguments for real-to-sim data generation:
Real reconstruction gives the simulator a grounded world; simulation gives the data engine privileged control and scalable expert generation.
OOJU and commercial real-to-sim systems
Commercial systems such as OOJU point to the same demand from industry: teams want tools that can convert real scenes or assets into reusable simulation environments for robot learning and evaluation.
The commercial interest is not surprising. Real-to-sim is one of the most obvious paths toward useful synthetic data because it reduces the gap between synthetic worlds and deployment environments.
The core challenge of real-to-sim
Real-to-sim engines are promising because they anchor simulation in reality. But they face hard questions:
| Challenge | Why it is hard |
|---|---|
| Reconstruction fidelity | Small geometry errors can break contact behavior |
| Physical properties | Mass, friction, compliance, and articulation are hard to infer from images |
| Editability | A reconstructed scene must be controllable, not just viewable |
| Scalability | Reconstruction pipelines can be expensive or manual |
| Evaluation | Visual realism does not guarantee policy transfer |
The simulation view makes one thing clear: real-to-sim is not solved by reconstruction alone. The reconstructed world must become an executable robot-learning environment.
6. Human-to-sim-to-robot engines: using simulation to harvest human behavior
Human behavior data is much more abundant than robot behavior data. Videos of people manipulating objects, moving through rooms, using tools, and coordinating their hands are everywhere.
The problem is that human data is not robot data. It usually lacks robot actions, robot proprioception, robot embodiment constraints, and robot-compatible contact dynamics.
Human-to-sim-to-robot methods use simulation as the conversion layer.
Human2Sim2Robot: from one human RGB-D video to dexterous robot policy
Human2Sim2Robot extracts object trajectories and hand-pose cues from a human RGB-D video, builds object-centric rewards, and uses simulation RL to train a dexterous policy.
The important idea is that the human video does not directly provide the robot trajectory. Instead, it provides task evidence: what object moved, how it moved, and what hand-object interaction may have occurred.
Simulation then generates the robot behavior that could accomplish the same object-centric outcome.
This is a powerful simulation pattern:
| Human video provides | Simulation must infer/generate |
|---|---|
| Object motion | Robot actions |
| Hand pose cues | Embodiment-specific contact behavior |
| Task intent | Reward function or objective |
| Visual context | Interactive environment |
The value of this approach is obvious. If it works, robot learning can draw from human videos instead of only robot demonstrations. The difficulty is equally obvious: inferring physical interaction from video is hard, and the robot may need to solve the task in a very different way from the human.
DexMan: generated or human videos as sources for dexterous simulation tasks
DexMan converts human or generated videos into simulation RL tasks with contact rewards, enabling humanoid bimanual dexterous policy rollouts.
This pushes the idea further. The source behavior may come not only from real human videos but also from generated videos. That makes simulation even more important because generated videos may be visually plausible but physically ambiguous.
The simulator becomes the filter. It must determine whether the behavior implied by the video can be turned into a physically valid robot task.
HERMES again: human motion as a prior, simulation as the adaptation engine
HERMES also belongs partly in this family because it transforms heterogeneous human motion data into physically plausible mobile bimanual dexterous behaviors.
The recurring theme is embodiment adaptation. Human motion is not the final answer. It is a behavioral prior. Simulation must retarget, optimize, and validate it under robot constraints.
The promise and risk of human-to-sim-to-robot data
Human behavior is attractive because it is abundant and diverse. But the farther the source data is from robot execution, the more the simulator must infer.
| Source data | Missing information |
|---|---|
| Human RGB video | Depth, contacts, forces, robot actions |
| Human RGB-D video | Robot embodiment and control |
| Human motion capture | Object dynamics and visual context |
| Generated video | Physical validity and action grounding |
This family may become extremely important, but it depends heavily on the quality of the simulation bridge. If the bridge is weak, the method may produce robot behavior that imitates the appearance of human action without capturing executable manipulation.
7. Comparing the engines from a simulation-building perspective
For building a real synthetic data generation stack, the practical question is not “which paper is best?” The better question is:
Which kind of simulation engine should I build first, and what bottleneck does it solve?
Here is a comparison from a simulation perspective:
| Engine type | Human effort | Scalability | Simulation dependence | Best use case | Main risk |
|---|---|---|---|---|---|
| Demo-to-sim replay | Medium | Medium-high | High | Expanding high-quality seed demonstrations | Breaks under geometry, contact, or embodiment changes |
| Programmatic expert factory | Low-medium after setup | High | Very high | Large-scale pretraining data | Script/planner bias and clean-state overfitting |
| RL rollout factory | Low after setup, high compute | High | Very high | Contact-rich behavior and recovery data | Reward hacking and sim exploitation |
| Real-to-sim reconstruction | Medium-high | Medium | Medium-high | Grounding synthetic data in real scenes | Reconstruction may be visual but not physically usable |
| Human-to-sim-to-robot | Low-medium for source data, high algorithmic burden | Potentially high | High | Harvesting human behavior sources | Embodiment mismatch and missing action/contact information |
A useful way to think about these engines is by their anchor:
| Engine | Anchor signal |
|---|---|
| Demo-to-sim replay | Robot demonstrations |
| Programmatic expert factory | Task programs and planners |
| RL rollout factory | Rewards and interaction |
| Real-to-sim reconstruction | Real scenes or real robot episodes |
| Human-to-sim-to-robot | Human behavior |
No anchor is perfect. Robot demonstrations are high quality but scarce. Scripts scale but may be biased. RL produces interaction but can exploit the simulator. Real reconstruction grounds the world but may not recover physical properties. Human behavior is abundant but not robot-executable.
The future stack will probably combine them.
8. What this means for building an SDG stack
From a simulation engineering perspective, the lesson is that synthetic data generation should not be designed as one monolithic method. It should be designed as a composable stack.
A practical robotics SDG stack should have at least three major layers:
| Layer | Purpose | Example components |
|---|---|---|
| World | Generate or reconstruct scenes, objects, materials, lighting, cameras | Isaac Sim / Isaac Lab assets, 3DGS reconstruction, scanned scenes, procedural layouts |
| Behavior | Generate robot actions and trajectories | Teleop replay, MimicGen-like transformation, scripted skills, TAMP, RL experts, human-video conversion |
| Evaluation | Decide whether generated data is useful | Simulation benchmarks, digital-twin validation, policy training curves, real/sim correlation |
This is close to a World / Behavior / Evaluation view of robot simulation.
World layer: simulation data starts with the environment
The world layer defines what the robot sees and touches. It includes:
- object assets,
- object placements,
- scene layouts,
- lighting and materials,
- camera viewpoints,
- collision geometry,
- physical properties,
- articulation and constraints.
A weak world layer creates weak data even if the behavior generator is strong. For example, a scripted expert may generate perfect trajectories in a clean tabletop scene, but the policy may fail in cluttered layouts with different lighting, occlusions, or object geometries.
Real-to-sim systems strengthen this layer by grounding scenes in reality. Procedural environment systems strengthen it by increasing diversity. High-quality rendering systems strengthen the visual distribution. Physics parameterization strengthens contact plausibility.
Behavior layer: simulation must produce actions, not just images
The behavior layer is where most of the surveyed methods live. It answers the question: who acts in the simulator?
Possible behavior sources include:
| Source | Strength | Weakness |
|---|---|---|
| Human teleoperation | High-quality intent and natural behavior | Expensive and narrow |
| Demo transformation | Efficient expansion from seed data | Limited by transformation validity |
| Scripted skills | Scalable and controllable | Brittle and biased |
| TAMP / motion planning | Geometrically reliable | Weak for contact-rich manipulation |
| RL experts | Interactive and robust under rewards | Expensive and simulator-sensitive |
| Human videos | Abundant and diverse | Missing robot actions |
A mature SDG system should not depend on one source. It should support multiple behavior generators and compare their usefulness.
Evaluation layer: synthetic data must close the loop
The evaluation layer is often underemphasized, but it is the difference between a data demo and a data engine.
Synthetic data generation should be judged by downstream policy improvement, not just by the number of generated trajectories.
Useful evaluation questions include:
| Question | Why it matters |
|---|---|
| Does the generated data improve policy success rate? | Measures actual training value |
| Does it improve robustness to object pose, geometry, and clutter? | Tests distribution coverage |
| Does it transfer to real or digital-twin scenes? | Tests sim-to-real relevance |
| Does it create useful failure and recovery states? | Tests contact and interaction diversity |
| Does more generated data keep helping, or saturate quickly? | Tests data quality and scaling law |
A good SDG pipeline should have a feedback loop:
- Generate worlds.
- Generate behaviors.
- Train policies.
- Evaluate on benchmark and digital-twin tasks.
- Identify failure modes.
- Generate targeted new data.
Without this loop, synthetic data generation becomes blind scaling.
9. A likely future direction: hybrid simulation engines
The strongest future systems will probably not belong to one category. They will combine multiple engines.
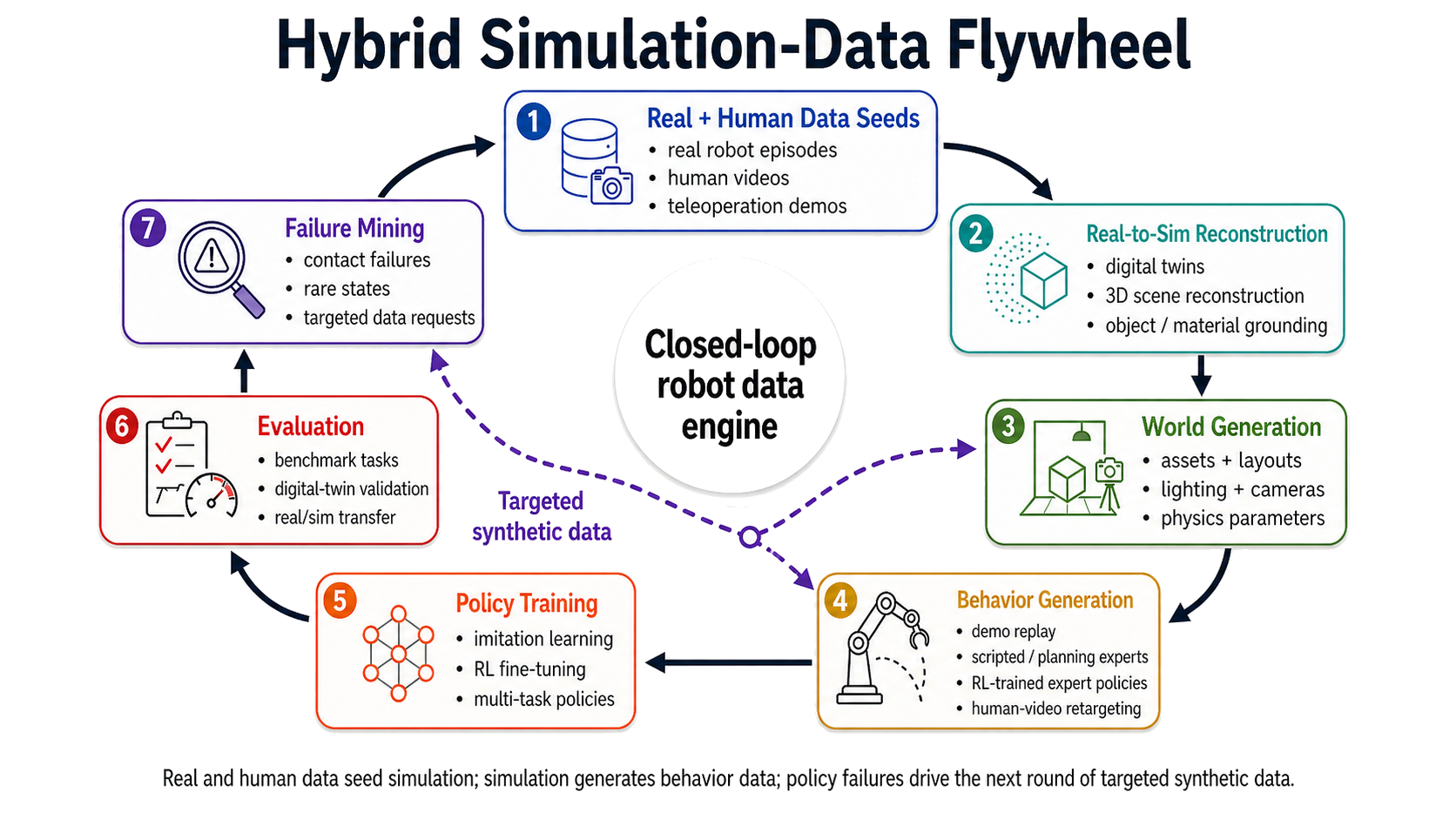
A realistic pipeline might look like this:
- Use real-to-sim reconstruction to create a small set of high-fidelity digital twins.
- Use teleoperation to collect a few high-quality seed demonstrations.
- Use MimicGen-like replay to expand object poses and scene variations.
- Use scripted experts and TAMP to generate broad task coverage.
- Use RL experts to add contact-rich recovery behavior.
- Use human videos to introduce new task priors.
- Use benchmark and digital-twin evaluation to decide which synthetic data is actually useful.
This hybrid view is important because each engine solves a different bottleneck:
| Bottleneck | Useful engine |
|---|---|
| Not enough high-quality trajectories | Demo-to-sim replay |
| Not enough task diversity | Programmatic expert factories |
| Not enough interaction robustness | RL rollout factories |
| Synthetic worlds are unrealistic | Real-to-sim reconstruction |
| Robot data is scarce but human data is abundant | Human-to-sim-to-robot conversion |
| Data quality is unclear | Evaluation and digital-twin validation |
The winning system is unlikely to be “the best single data-generation paper.” It will be the system that connects these engines into a controllable, measurable, and repeatable simulation pipeline.
10. Conclusion: simulation is becoming the data engine
The central shift in robot data generation is not simply that researchers are generating more synthetic trajectories. The deeper shift is that simulation is becoming the organizing infrastructure for robot data.
Earlier pipelines often treated simulation as a place to replay demonstrations or train isolated policies. Newer systems increasingly treat simulation as a full data engine: a place to construct worlds, generate behavior, enforce physics, render observations, train experts, replay real episodes, convert human motion, and evaluate policy improvement.
This changes how we should think about robot learning infrastructure.
The question is no longer:
Should we use real data or synthetic data?
The better question is:
Which parts of the robot data distribution should come from real demonstrations, which should come from reconstructed digital twins, which should come from scripted or planned experts, which should come from RL interaction, and which can be inferred from human behavior?
From a simulation perspective, post-2024 robot data generation is moving toward a composable stack:
World generation + behavior generation + physics validation + policy evaluation.
That is the real direction of the field. The future of robot data is not just more teleoperation, and it is not just prettier simulation. It is simulation infrastructure that can manufacture useful behavior at scale while staying grounded enough to matter for real robots.
References and project pages
Each item lists the project page first and the arXiv page second when available.
- MimicGen: project · arXiv
- SkillMimicGen: project · arXiv
- DexMimicGen: project · arXiv
- CP-Gen: project · arXiv
- SoftMimicGen: project · arXiv
- DemoGen: project · arXiv
- MoMaGen: project · arXiv
- AutoMoMa: project · arXiv
- ReinforceGen: project · arXiv
- ExpertGen: project · arXiv
- PhysicsGen: project · arXiv
- InternData-A1: project · arXiv
- AutoDataGen: project/code
- AnyTask: project · arXiv
- HumanoidGen: project · arXiv
- RoboVerse: project · arXiv
- ManiSkill: project · arXiv
- AgentWorld: project · arXiv
- RLDG: project · arXiv
- X-Sim: project · arXiv
- HERMES: project · arXiv
- ReBot: project · arXiv
- RoboSimGS: project · arXiv
- Real2Render2Real: project · arXiv
- Re³Sim: project · arXiv
- OOJU: project
- Human2Sim2Robot: project · arXiv
- DexMan: project · arXiv